

Proteínas são as mais abundantes moléculas dos seres vivos. Correspondem a 50% da massa seca das células e são um dos componentes básicos da dieta dos organismos, juntamente com os lipídeos e carboidratos. Elas podem apresentar formas e tamanhos diferentes, enquanto algumas são longas e fibrosas, outras são finas e fibrosas ou globulares. Uma célula pode conter centenas de diversas proteínas trabalhando ao mesmo tempo em funções completamente distintas [1-2].
Afinal, o que são proteínas?
Proteínas são polímeros produzidos no interior das células dos seres vivos e que norteiam praticamente todas as suas reações fisiológicas. Atuam como catalisadores de reações químicas, compõem os tecidos e músculos, mediam transporte de substâncias e outras moléculas essenciais, participam ativamente da sinalização celular e ainda estão presentes no seu próprio processo de síntese [1]. Elas são formadas por unidades menores chamadas de aminoácidos (Figura 1), que são moléculas orgânicas que apresentam uma região comum denominada de esqueleto peptídico, formado por radicais orgânicos que se ligam ao mesmo átomo de carbono e diferem-se a partir da cadeia lateral que lhes confere características diferentes. Para que uma proteína seja formada, uma sequência de aminoácidos é conectada por uma interação química chamada ligação peptídica (Figura 1).

Figura 1. Esqueleto peptídico dos aminoácidos. O carbono alfa (centro), ligado à carboxila (COOH–), a um grupo amino (NH3+), um Hidrogênio (H) e a um radical que varia para cada aminoácido. Fonte: Khemis (CC-BY 4.0) [3].
Na ligação peptídica, a carboxila (COOH–) de um aminoácido e o grupo amino (NH3+) do aminoácido adjacente reagem, para formar um grupo amida que compõe as cadeias polipeptídicas. O processo tem como resultante a interação dos aminoácidos, que passam a ser resíduos por se apresentarem diferentes da sua forma livre, e moléculas de água [1-2].
O genoma humano codifica um total de 20 aminoácidos para construir proteínas, que podem ser classificados como essenciais, quando o próprio organismo tem a capacidade de produzi-los, e não essenciais, quando precisam ser obtidos via nutrição [2]. O entendimento sobre aminoácidos e ligações peptídicas são a base para desvendar a origem das proteínas de tamanhos e formas variadas. Nas sessões seguintes exploraremos a síntese dessas estruturas e as diferentes formas assumidas por elas.
Síntese de proteínas
A síntese é um processo de alta complexidade biológica que necessita de um maquinário especializado (proteínas específicas, ácidos nucleicos, ribossomos, aminoácidos, etc). O DNA, que contém a informação para a produção da proteína, tem uma fração sua (um gene) transcrita para RNA, que ao migrar do núcleo para o citoplasma é lido por um complexo ribossomal que traduz a informação genética [1-2].
O processamento da informação na síntese pode ser dividido em duas etapas: a primeira, chamada de transcrição (Figura 2), inicia-se no interior celular, no caso de organismos procariontes. Nos eucariontes, o processo começa no núcleo celular, com a ação da enzima RNA polimerase. Essa enzima se liga à região promotora, que antecede o gene de interesse, para a produção de uma fita de RNA mensageiro a partir da fita de DNA (sentido 3’-5’). O RNA mensageiro é sintetizado considerando a mesma regra de pareamento de bases que o DNA, mas adota um diferencial alterando as ligações Adenina – Timina por Adenina – Uracila. O processo ocorre até que um códon de terminação (U-A-A, U-A-G ou U-G-A) seja compreendido pela enzima, indicando o fim do gene e da etapa transcricional [4].

Figura 2. Etapa de transcrição do DNA. A dupla fita de DNA é desdobrada por ação da RNA polimerase, permitindo a transcrição da informação genética para RNA mensageiro. Fonte: Sulai (Domínio público) [5].
O pré-mRNA permanece no núcleo celular dos eucariontes para que seja submetido a um tipo de curadoria biológica que se chama splicing, onde porções transcritas e não codificantes são retiradas da sequência [4]. Duas modificações importantes ocorrem na nova fita pela adição de grupos químicos em suas extremidades. A cap 5’, que é uma guanina modificada (G), é adicionada na extremidade 5’ para impedir rompimentos por ação de fosfatases e nucleases e, mais tarde, mediar a ligação do complexo enzimático que codifica a proteína no citoplasma, enquanto uma sequência de aproximadamente 200 adeninas (cauda poli-A) é adicionada na extremidade 3’ para proteger o transcrito e conferir maior estabilidade à molécula [1-2].
Com a retirada dos íntrons, e demais modificações, o mRNA se torna legível para os ribossomos, que consideram que a cada três nucleotídeos (um códon), um aminoácido seja adicionado à sequência (Figura 3). Assim, a leitura é baseada nos 61 códons do DNA que podem ser transcritos para codificar os aminoácidos necessários à proteína. Essa relação é chamada de código genético [1].
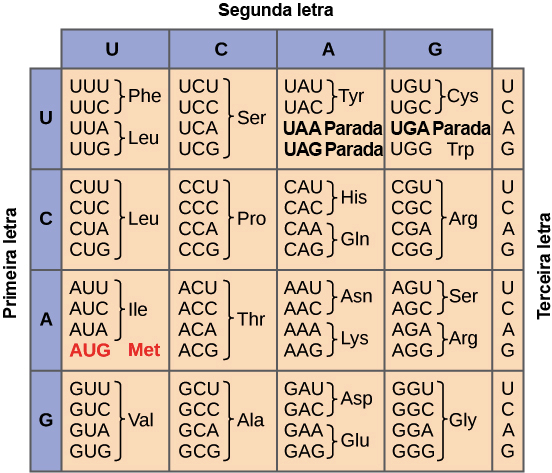
Figura 3. O código genético. Tabela do código genético que relaciona os códons aos respectivos aminoácidos. Fonte: traduzido de Nirenberg/Khorana [6].
A segunda etapa, conhecida como tradução, ocorre com a saída do RNA mensageiro do núcleo para o citoplasma, e conta com a ação dos outros dois tipos de RNA: ribossômico e transportador, para que a síntese seja possível.
Ao chegar no citoplasma, dos eucariontes, a fita de RNA mensageiro se junta ao ribossomo, que inicia a leitura a partir do códon A-U-G, no sentido 5’-3’. O complexo ribossomal, media a ligação entre as moléculas de RNA transportador, que carregam novos aminoácidos, com a fita de RNA mensageiro, permitindo a interação dos códons com os anticódons (Figura 4) [1-4].
 Figura 4. Etapa de tradução. O complexo ribossomal se junta a fita de RNA mensageiro e permite a ligação do RNA transportador, carregando aminoácidos, pelo pareamento dos anticódons a seus respectivos códons. Fonte: traduzido de Sarah Greenwood (CC-BY 4.0) [7].
Figura 4. Etapa de tradução. O complexo ribossomal se junta a fita de RNA mensageiro e permite a ligação do RNA transportador, carregando aminoácidos, pelo pareamento dos anticódons a seus respectivos códons. Fonte: traduzido de Sarah Greenwood (CC-BY 4.0) [7].
Após a metionina, um segundo tRNA é recebido no sítio ribossomal, carregando o próximo aminoácido que será adicionado à sequência. A ligação peptídica é estabelecida entre os dois e o primeiro RNA transportador é liberado, fazendo o segundo ser transferido para outro sítio e o ribossomo se deslocar na fita do mRNA para receber o próximo. Dessa forma, a fita é percorrida mediante a leitura e o processo continua até que um códon de terminação seja reconhecido pelo complexo para que haja a liberação da proteína, a separação do ribossomo e o fim da etapa de tradução [2-4].
Estruturas de proteínas
Ao serem sintetizadas, as proteínas passam a ser classificadas quanto ao nível conformacional adquirido (Figura 5), uma vez que a conformação tridimensional, se refere às diversas formas que elas podem assumir devido suas ligações, variando em complexidade e funções específicas [8].
A estrutura primária, como pode ser visto na Figura 5, é o nível mais básico de organização estrutural das proteínas, caracterizada por uma sequência de aminoácidos residuais que é quimicamente estabilizada pela ligação peptídica. Essa sequência proteica é determinada pelo gene que a codifica. Uma modificação substitutiva ou deletéria nos resíduos pode gerar mudanças conformacionais, resultando em desdobramentos parciais e perda da função biológica [1-8].
Arranjos formados pelo dobramento da cadeia principal da estrutura primária, constituem a estrutura secundária (Figura 5). Dentre os dobramentos mais recorrentes estão as alfa-hélices, conformações e voltas beta, que apresentam-se nas formas helicoidal, pregueada e espiral randômica, respectivamente. Essa classificação se refere à disposição espacial dos resíduos de aminoácidos, e consequentemente, a qualquer segmento da cadeia polipeptídica, sem considerar a posição das cadeias laterais e relações com outras partes [8-9]. Existem ainda estruturas secundárias que fogem a regra, não apresentando um padrão definido, impossibilitando a descrição adequada dos segmentos por apresentarem aleatoriedade espacial [1].
A estrutura terciária (Figura 5), é conhecida como forma nativa da proteína, considera o arranjo tridimensional total dos átomos que a compõem e resulta principalmente das interações entre radicais dos aminoácidos [8]. Os resíduos que estavam distantes na sequência polipeptídica ou em diferentes estruturas secundárias, com o dobramento da proteína, podem interagir com base em seus grupos carregados, mantendo suas posições terciárias por diferentes tipos de interações. Com forças de repulsão e atração, os grupos radicais se estabilizam espacialmente por ligações não covalentes, como hidrogênio, iônicas, interações dipolo-dipolo e forças de dispersão de London. As interações hidrofóbicas são importantes para a estabilidade da proteína, bem como as ligações dissulfeto, que ocorrem entre cadeias de cisteína contendo enxofre, unindo segmentos distintos [1-9].
Arranjos formados por proteínas de nível terciário, constituem as estruturas quaternárias, que são duas ou várias proteínas aglomeradas, por forças eletrostáticas, para formação de um complexo funcional maior [8-9], como pode ser visto ainda na Figura 5. Nesse quarto e último nível de organização, elas podem ser divididas em: proteínas fibrosas; proteínas globulares; proteínas intrínsecamente desordenadas e proteínas de membrana [10].
 Figura 5. Níveis de organização das cadeias polipeptídicas. Estrutura primária representada por uma sequência de resíduos de aminoácido; Estrutura secundária representada pelos arranjos de alfa-hélice e folha-beta; Estrutura terciária: representada por um conjunto de arranjos secundários; Estrutura quaternária: formada por um conjunto de estruturas terciárias. Fonte: Thomas Shafee (CC-BY 4.0) [11].
Figura 5. Níveis de organização das cadeias polipeptídicas. Estrutura primária representada por uma sequência de resíduos de aminoácido; Estrutura secundária representada pelos arranjos de alfa-hélice e folha-beta; Estrutura terciária: representada por um conjunto de arranjos secundários; Estrutura quaternária: formada por um conjunto de estruturas terciárias. Fonte: Thomas Shafee (CC-BY 4.0) [11].
Ao assumir sua estrutura nativa, as proteínas tornam-se funcionais e participam de diversos processos fisiológicos. Suas funções, estabilidade, expressão e solubilidade são propriedades amplamente estudadas a partir da identificação da sequência primária e da análise do enovelamento da cadeia polipeptídica [8-10]. Elas também apresentam padrões identificáveis no enovelamento, que constituem os motivos e domínios, que são comumente utilizados para entender estruturas ainda não resolvidas.
Conclusão
Este artigo apresenta resumidamente uma resposta à pergunta sobre a origem das proteínas. A partir desse conhecimento, podemos explorar outros processos complexos, como o surgimento de modificações pós-traducionais e a dinâmica do próprio dobramento das cadeias proteicas. Mas isso é um assunto para os próximos artigos.
Referências
[1] Nelson, D. L., M. Cox. Princípios de Bioquímica. 2. ed. São Paulo: Sarvier, 2000.
[2] Alberts, Bruce; et al. Biologia Molecular da Célula. 5.ed. Porto Alegre: Artmed, 2010.
[3] Khemis. (CC-BY 4.0). Disponível em: https://pt.m.wikipedia.org/wiki/Ficheiro:Peptidformationball_pt_BR.svg. Acesso em 18 de Agosto de 2023.
[4] Berg, J.M.; Tymoczko, J.L.; Stryer, L. Bioquímica. 6° ed. Rio de Janeiro: Guanabara Koogan, 2008.
[5] Sulai. Domínio público. Dispovível em: https://commons.wikimedia.org/wiki/File:DNA_transcription.svg. Acesso em 18 de Agosto de 2023.
[6] Nirenberg/Khorana: Breaking the genetic code. (s.d.). Obtido em http://www.mhhe.com/biosci/genbio/raven6b/graphics/raven06b/howscientiststhink/14-lab.pdf. Acesso em 18 de Agosto de 2023.
[7] Sarah Greenwood (CC-BY 4.0). Disponível em: https://commons.wikimedia.org/wiki/File:Protein_Synthesis-Translation.png. Acesso em 18 de Agosto de 2023.
[8] Verli, H. et al. Bioinformática da Biologia à flexibilidade molecular. Porto Alegre, 2014.
[9] Zaha, A.; Ferreira, H. B.; Passaglia, L. M. P.; Biologia Molecular Básica. 5ª edição. Porto Alegre: Artmed, 2014.
[10] Lemos, R. P.; Santos, P. H.; Rocha, A. Introdução à Biologia Estrutural de Proteínas. Revista BIONFO. Disponível em: https://bioinfo.com.br/introducao-a-biologia-estrutural-de-proteínas. Acesso em 14 de Agosto de 2023.
[11] Thomas Shafee (CC-BY 4.0). Disponível em: https://commons.wikimedia.org/wiki/File:Protein_structure_(full).png#/media/File:Protein_structure_(full).png. Acesso em 18 de Agosto de 2023.
Autores:
Alisson Clementino da Silva https://orcid.org/0000-0003-0622-5561,
Bruno Rafael Pereira Nunes https://orcid.org/0000-0002-2665-1616,
Joicymara Xavier https://orcid.org/0000-0002-4649-6270
Revisão: Marcos Antonio Nobrega de Sousa, Wylerson Nogueira
Cite este artigo:
Silva, AC; Nunes, BRP; Xavier, J. De onde vêm as proteínas? BIOINFO. ISSN: 2764-8273. Vol. 3. p.16 (2023). doi: 10.51780/bioinfo-03-16
[…] De onde vêm as proteínas? […]
[…] De onde vêm as proteínas? […]