
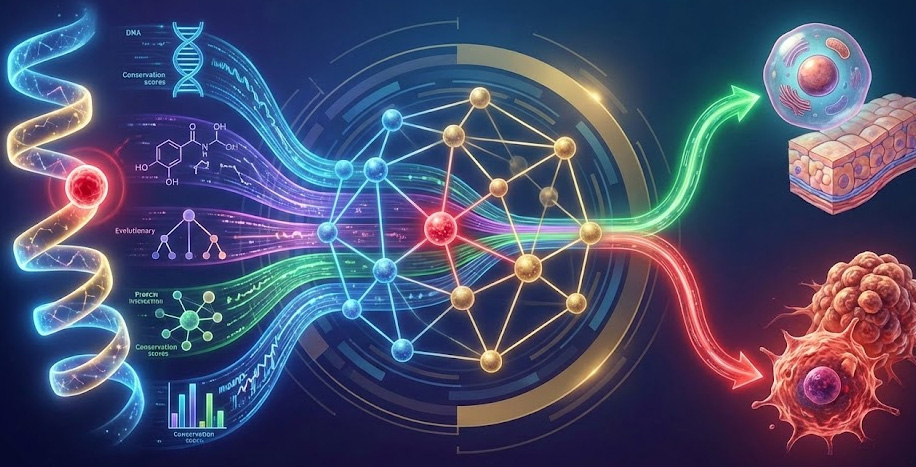
O aprendizado multimodal tem se consolidado como abordagem promissora para lidar com a heterogeneidade e a complexidade dos dados biomédicos, especialmente em doenças como o câncer. Ao integrar descritores de múltiplas modalidades, esses modelos aprendem representações latentes mais expressivas e robustas a mudanças na distribuição dos dados, inclusive em cenários com poucos rótulos. Neste trabalho, discutimos fundamentos de aprendizado de representação multimodal e o papel de arquiteturas modernas, como Transformers e redes neurais de grafos, na modelagem de dependências de longo alcance e estruturas relacionais. Em particular, comparamos duas técnicas centrais de representação: (i) representação conjunta e (ii) representação coordenada. Por fim, destacamos aplicações recentes e desafios em interpretabilidade e robustez.
Autores: Lucas Moraes dos Santos, Tatiane Senna Bialves, Raquel Cardoso de Melo-Minardi
1. Aprendizado Multimodal
Tecnologias transformadoras como o sequenciamento de nova geração (NGS) têm revolucionado a bioinformática ao viabilizar a geração em larga escala de dados biológicos complexos [1,2]. Conjuntos de dados heterogêneos demandam métodos multimodais que combinam diferentes tipos de informação para elucidar sistemas e processos biológicos [3,4]. Nesse contexto, o aprendizado multimodal é um subcampo do aprendizado de máquina cujo objetivo é desenvolver modelos capazes de processar e relacionar descritores de diversas modalidades, para aprimorar o desempenho preditivo [3]. Um exemplo é a integração de dados de morfologia histopatológica (imagens) com os de transcriptômica (e.g., dados de expressão gênica), resultando em técnicas como a transcriptômica espacialmente resolvida, que possibilitam a análise da expressão gênica em seu contexto espacial [5].
Uma abordagem comum no aprendizado profundo é aprender representações numéricas, ou embeddings, em um espaço latente de baixa dimensionalidade e, no contexto multimodal, alinhá-las para que elementos semanticamente equivalentes ocupem regiões próximas nesse espaço [3,5]. Para viabilizar esse alinhamento em dados sequenciais, mecanismos de atenção, introduzidos por Bahdanau et al. (2014), permitem que o modelo ajuste dinamicamente o foco em partes da entrada [6]. Os Transformers (Vaswani et al., 2017) generalizam esse princípio por meio de autoatenção (self-attention), dispensando a recorrência das redes neurais recorrentes e modelando dependências de longo alcance [7].
Além disso, em cenários onde relações entre modalidades assumem uma estrutura de rede (e.g., interações em proteínas), as redes neurais de grafos (RNG) oferecem uma abordagem expressiva e agnóstica para modelar interdependências em dados multimodais [8]. As RNGs aprendem representações de nós, arestas, subgrafos e grafos inteiros por meio de estratégias de propagação de mensagens (message passing) [4]. Nesse sentido, o aprendizado multimodal em grafos combina diferentes modalidades e aprende dependências intermodais a partir da estrutura do grafo. Modelos como o AlphaFold [9], uma rede neural profunda que representou um avanço significativo na predição estrutural, preveem estruturas 3D usando grafos de resíduos a partir de dados de homologia de sequência [4].
No contexto biomédico, doenças multifatoriais como o câncer apresentam acentuada heterogeneidade em nível tecidual, tornando crítica a integração de dados [5]. A literatura sugere que padrões de sequência e propriedades estruturais em genes reguladores modulam sua elevada flexibilidade conformacional e, consequentemente, sua maior tolerância ao acúmulo de mutações [10]. Essas alterações, ao comprometerem a função e a estabilidade proteicas, estariam envolvidas no processo de carcinogênese. Assim, hipotetizamos que abordagens de fusão multimodal são promissoras não apenas para prever mutações clinicamente relevantes com maior precisão [2], mas também para fornecer um esquema inicial para a compreensão mecanicista subjacente ao desenvolvimento tumoral.
2. Representação Multimodal
Nas últimas décadas, o aprendizado profundo (deep learning) tem mostrado grande potencial para identificar características e relações em grandes volumes de dados, oferecendo insights biológicos relevantes e aprimorando a caracterização de patologias [1,2]; ainda assim, a heterogeneidade intrínseca de doenças complexas, como o câncer, é frequentemente tratada de forma limitada por modelos unimodais [2]. Nesse contexto, o aprendizado multimodal busca integrar descritores heterogêneos provenientes de diferentes modalidades a fim de desenvolver modelos mais generalizáveis, robustos a mudanças nas distribuições de dados e eficientes em cenários com poucos dados rotulados [4].
A integração dessas informações é viabilizada pelo aprendizado de representação (representation learning), que aprende representações eficazes e seus mapeamentos diretamente a partir dos dados, formando espaços latentes expressivos nos quais relações semânticas podem ser inferidas [1,3]. No contexto multimodal, essa abordagem integra informações de múltiplas modalidades (por exemplo, imagens e texto) [9]. Nesse cenário, arquiteturas Transformer têm se destacado por sua escalabilidade e pela capacidade de modelar diferentes modalidades com menos suposições arquitetônicas específicas [8].
As abordagens de representação podem ser categorizadas em duas estratégias centrais:
-
A representação conjunta (joint representation) refere-se à projeção de representações unimodais em um espaço multimodal [8], sendo utilizada em tarefas nas quais dados multimodais estão disponíveis no treinamento e na inferência. Geralmente, esse processo envolve a concatenação das modalidades (ou características) de entrada antes da projeção (fusão antecipada) [5]. No campo da bioinformática, por exemplo, avanços recentes integram informações de sequência e de estrutura usando modelos de linguagem de proteínas pré-treinados e redes neurais profundas geométricas [11]. Essas abordagens têm sido empregadas para avaliar a qualidade de modelos [11], pontuar poses de acoplamento (docking) [12], determinar a afinidade de ligação de ligantes [11] e prever o efeito funcional de variantes missense [13];
-
A representação coordenada (coordinated representation) mapeia cada modalidade em seu respectivo espaço latente por meio de um codificador (encoder) dedicado [3]. Nesse caso, as representações são alinhadas por meio de uma função de perda contrastiva (aprendizagem contrastiva), cujo objetivo é minimizar a distância entre as representações de pares semanticamente correspondentes (positivos) e maximizá-la entre pares não correspondentes (negativos), preservando a independência de cada projeção unimodal [9]. Um exemplo é treinar ativamente o modelo a mapear a região de pixels que forma um ‘rosto sorridente’ em uma imagem diretamente aos tokens exatos da palavra ‘sorriso’ na legenda, resultando em uma representação onde ambos os conceitos são mapeados para regiões muito próximas no espaço latente.
3. Conclusão
O aprendizado multimodal representa uma alternativa promissora à heterogeneidade de dados biomédicos, superando limitações de abordagens unimodais e impulsionando tarefas críticas em bioinformática. A representação conjunta favorece cenários com dados multimodais disponíveis no treino e na inferência, enquanto a representação coordenada mantém especificidades por modalidade e habilita alinhamento para pareamento entre domínios. Na bioinformática, essas estratégias têm demonstrado eficácia na avaliação de modelos, docking, estimação de afinidade e predição de efeitos de variantes. Como perspectivas, destacam-se: (i) o desenvolvimento de benchmarks que cubram diferentes combinações de modalidades; (ii) o aprimoramento da interpretabilidade e da validação biológica das representações; (iii) o pré-treino autossupervisionado em larga escala; e (iv) protocolos de robustez e generalização a mudanças de distribuição — condição comum em dados biomédicos.
Agradecimentos. Os autores agradecem às agências de fomento à pesquisa: CAPES, CNPq e Fapemig.
4. Referências
[1] Min, S; Lee, B; Yoon, S. Deep learning in bioinformatics. Brief. Bioinform. ISSN: 1467-5463. Vol. 18. p. 851–869 (2016). doi: https://doi.org/10.1093/bib/bbw068
[2] Steyaert, S; Pizurica, M; Nagaraj, D. Multimodal data fusion for cancer biomarker discovery with deep learning. Nat. Mach. Intell. ISSN: 2522-5839. Vol. 5. p. 351–362 (2023). doi: https://doi.org/10.1038/s42256-023-00633-5
[3] Akkus, C; Chu, L; Djakovic, V. Multimodal deep learning. arXiv [Preprint]. (2023). doi: g/10.48550/arXiv.2301.04856
[4] Ektefaie, Y; Dasoulas, G; Noori, A. Multimodal learning with graphs. Nat. Mach. Intell. ISSN: 2522-5839. Vol. 5, n. 4. p. 340–350 (2023). doi: https://doi.org/10.1038/s42256-023-00624-6
[5] Acosta, JN; Falcone, GJ; Rajpurkar, P. Multimodal biomedical AI. Nat. Med. ISSN: 1078-8956. Vol. 28, n. 9. p. 1773–1784 (2022). doi: https://doi.org/10.1038/s41591-022-01981-2
[6] Vaswani A et al. Attention Is All You Need. Adv. Neural Inf. Process. Syst. 30:5998–6008 (2017). https://arxiv.org/abs/1706.03762
[7] Xu, P; Zhu, X; Clifton, DA. Multimodal learning with Transformers: A survey. IEEE Trans. Pattern Anal. Mach. Intell. Vol. 45, n. 10. p. 12113–12132 (2023). doi: https://doi.org/10.1109/TPAMI.2023.3275156
[8] Baltrušaitis, T; Ahuja, C; Morency, L-P. Multimodal Machine Learning: A Survey and Taxonomy. IEEE Trans. Pattern Anal. Mach. Intell. Vol. 41, n. 2 p. 423–443 (2019). doi: https://doi.org/10.1109/TPAMI.2018.2798607
[9] Jumper, J et al. Highly accurate protein structure prediction with AlphaFold. Nature 596, 583–589 (2021). doi: https://doi.org/10.1038/s41586-021-03819-2
[10] Chillón-Pino, D et al. Protein structural context of cancer mutations reveals molecular mechanisms and candidate driver genes. Cell Rep. 43, 114905 (2024). doi: https://doi.org/10.1016/j.celrep.2024.114905
[11] Wu, F et al. Integration of pre-trained protein language models into geometric deep learning networks. Commun. Biol. 2023;6(1):876. https://doi.org/10.1038/s42003-023-05133-1
[12] Xu, X; Bonvin, AMJJ. DeepRank-GNN-esm: A graph neural network for scoring protein–protein models using protein language model. Bioinformatics Adv. 2024;4(1):vbad191. https://doi.org/10.1093/bioadv/vbad191
[13] Zhang, H et al. Predicting functional effect of missense variants using graph attention neural networks. Nat Mach Intell. 2022;4(11):1017–1028. doi: https://doi.org/10.1038/s42256-022-00561-w