
A inteligência artificial não é nem artificial, nem inteligente.
Prof. Dr. Miguel Nicolelis (Duke University, E.U.A.)
Autores: Aristóteles Góes Neto e Thiago Miguelito Navarro de Camargo
Inteligência Artificial (IA) compreende um campo de conhecimento transdisciplinar (abrangendo Ciências Exatas, Ciências da Vida e Humanidades como campos basilares) cujo objetivo é criar sistemas capazes de realizar tarefas que, quando realizadas por seres humanos, tendem geralmente a ser associadas com inteligência [1]. Entretanto, inteligência é um termo atrelado a um conceito abstrato, complexo e razoavelmente complicado de, inclusive, ser adequadamente definido, pois está muito impregnado por uma visão fortemente antropocêntrica. Antropocentricamente definida, inteligência compreenderia raciocínio e capacidade de resolução de problemas, bem como todos os conceitos diretamente acoplados a esses atributos, como, por exemplo, capacidade lógica, compreensão, raciocínio, planejamento, criatividade e pensamento crítico. Todavia, adotando uma visão mais ampla e geral, e dentro de um arcabouço biológico e, consequentemente, evolutivo, inteligência pode ser entendida como: (i) percepção de informações, (ii) retenção como conhecimento (memória) e (iii) aplicação desse conhecimento por comportamentos adaptativos em um determinado contexto (ambiente). Dessa forma, escapa-se da visão antropocêntrica forte, dominante em todas as Ciências Sociais e Humanas, contextualizando-a em toda a dimensão biológica [5].
Os primórdios da Inteligência Artificial se confundem com o próprio desenvolvimento da Computação como Ciência. Nada mais nada menos que o próprio Alan Turing em pessoa foi quem teorizou sobre a possibilidade de máquinas “inteligentes” e desenvolveu um método que acreditava ser suficiente para a avaliação da “inteligência” de computadores, o famoso Teste de Turing [12]. Contudo, o termo “Inteligência Artificial” somente foi cunhado, alguns anos após esse clássico trabalho de Turing, durante um, também muito famoso, evento em que se discutiu extensivamente como tornar computadores capazes de usar linguagem, formar abstrações e conceitos e resolver tipos de problemas anteriormente reservados apenas aos seres humanos. Nesta Conferência no Darthmouth College (E.U.A.) se reuniram os grandes pesquisadores atuantes das mais diversas áreas da Ciência, como, por exemplo: McCarthy, Shannon, Wiener, Minsky, Rochester, Newell, Simon (entre muitos outros não citados aqui), considerados como os fundadores de um campo de conhecimento nascente denominado de… Inteligência Artificial (IA) [8].
Ao longo desses quase 70 anos de existência (sim, o que se chama de I.A. é muito mais antigo do que a maioria esmagadora das pessoas imagina!), esse campo de conhecimento, I.A., atravessou por momentos de intensa atividade, criatividade, e produtividade, mas também por momentos de descrença generalizada (conhecidos, inclusive, pela denominação de “invernos da I.A.”) [6]. Embora toda e qualquer categorização de áreas dentro de um campo de conhecimento científico apresente sempre no seu âmago uma certa dose de subjetividade, baseada, obviamente, nos critérios que foram utilizados, mesmo assim são altamente relevantes para uma melhor compreensão dos objetos de estudo e como eles se relacionam. De uma maneira geral, o campo de conhecimento denominado de Inteligência Artificial envolve: (i) Aprendizado de Máquina, (ii) Processamento de Linguagem Natural, (iii) Visão Computacional, (iv) Robótica, (v) Sistemas Especialistas e Representação do Conhecimento, (vi) Planejamento e Raciocínio, (vii) Inteligência Artificial Distribuída e (viii) Inteligência Artificial Emocional (Figura 1).
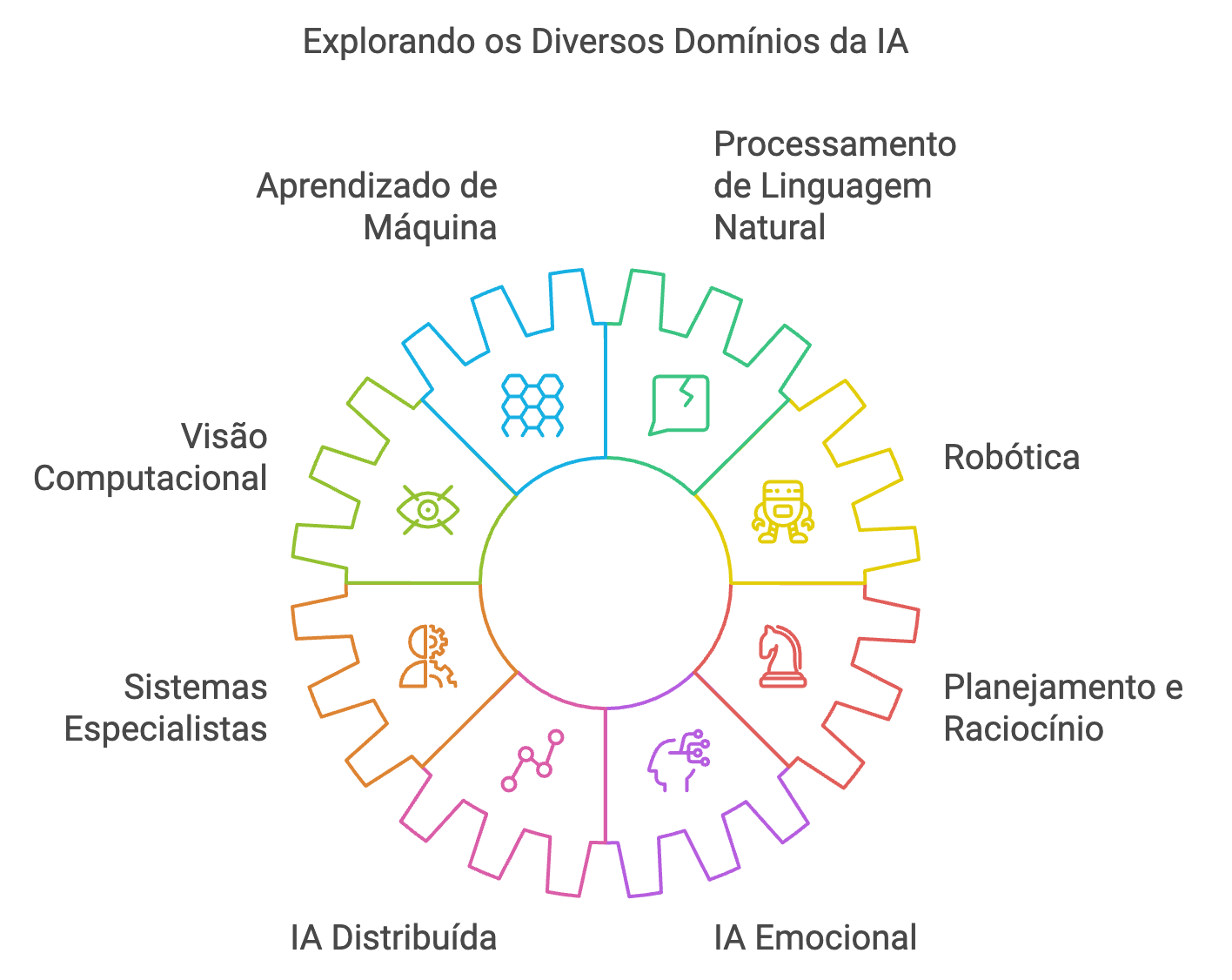 Figura 1. Explorando os diversos domínios da IA.
Figura 1. Explorando os diversos domínios da IA.
Partindo de um ponto de vista estritamente direcionado às aplicações de ferramentas de I.A. para a Bioinformática / Biologia Computacional, certamente as áreas de (i) Aprendizado de Máquina (AM), (ii) Processamento de Linguagem Natural (PLN) e (iii) Visão Computacional (VC) são as que, naturalmente, oferecem a maior gama de aplicabilidades possíveis, uma vez que os dados da área de Bioinformática são principalmente de (mas não restrito somente a) textos (ex. sequências de ácidos nucléicos e proteínas) e imagens (ex. fotografias digitais de macro ou micro-organismos e suas partes dentro da área de Bioinformática aplicada {à Biodiversidade ou Ecoinformática) e vídeos (ex. dinâmica molecular de proteinas).
O Aprendizado de Máquina pode ser classicamente dividido em Supervisionado, Não-Supervisionado e Semi-Supervisionado, por Reforço e Profundo (Deep Learning) (Figura 2). Já o Processamento de Linguagem Natural engloba Análise Sintática e Semântica, Tradução Automática, Geração de Linguagem Natural (Generative AI), enquanto que a Visão Computacional compreende Reconhecimento de Imagens e Padrões, Detecção e Segmentação de Objetos, e Visão 3D e Reconstrução de Imagens.
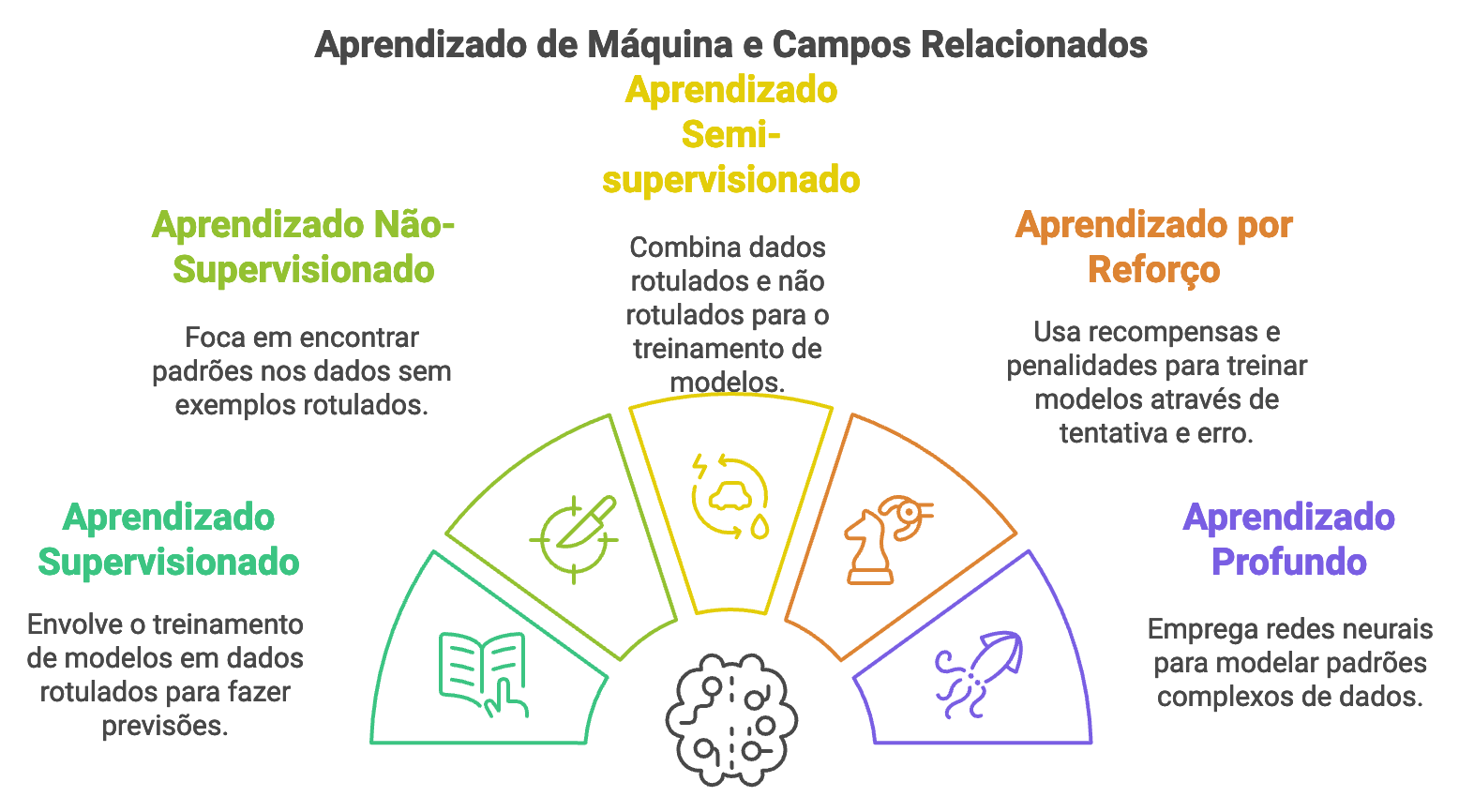 Figura 2. Aprendizado de máquina e campos relacionados.
Figura 2. Aprendizado de máquina e campos relacionados.
Em geral, e diferentemente do que se pensa, os algoritmos e modelos utilizados por essas distintas áreas da Inteligência Artificial podem ser exclusivos, mas, frequentemente, são compartilhados entre distintas áreas de modo que, atualmente, o Aprendizado de Máquina Profundo (Deep Learning) e, especialmente, o que vem sendo denominado de Inteligência Gerativa (lembrar que generativa vem de generar, que não existe na língua portuguesa!) usam indistintamente redes neurais profundas (com muitas camadas ocultas) com diferentes arquiteturas e com um número muito grande de parâmetros continuamente otimizados de forma automática, além de, obviamente, lidarem com uma quantidade extraordinária de dados de todos os tipos, tanto estruturados como não-estruturados.
As aplicações da Inteligência Artificial na Bioinformática / Biologia Computacional são amplas e praticamente qualquer novo artigo em periódicos científicos geralmente trará alguma análise realizada a partir de algoritmos / modelos baseados em Inteligência Artificial e, especificamente dentro das áreas de Aprendizado de Máquina, Processamento de Linguagem Natural Avançada (utilizando, por exemplo, os grandes modelos de linguagem ou LLMs, no acrônimo de língua inglesa) e Visão Computacional assistida por Aprendizado Profundo.
A Bioinformática / Biologia Computacional lida com a geração, armazenamento, análise, interpretação e administração de vastas quantidades de dados biológicos volumosos (quantidade), variáveis (estrutura) e velozes (velocidade de produção especialmente em séries temporais). A integração de técnicas de IA a Bioinformática / Biologia Computacional permite a extração de informações significativas e relevantes desses dados, acelerando descobertas científicas em todos as suas subáreas bem como, mais recentemente com os grandes modelos de linguagem, a geração de dados sintéticos e novos.
Didaticamente, pode-se dividir as áreas da Bioinformática/Biologia Computacional de acordo com o tipo de molécula trabalhada, tanto ao nível de sequências, estruturas, funções e padrões, e um eixo mais temático perpassando todas as áreas: (i) Ácidos Nucleicos (DNA e RNA) e suas interações, (ii) Proteínas e suas interações, (iii) Pequenas moléculas e suas interações, e (iv) Bancos de Dados, Meta-análises e Síntese Científica.
Diversos algoritmos de Aprendizado de Máquina vêm sendo utilizados para a análise de dados genômicos e transcriptômicos. Esses algoritmos conexionistas, simbolistas, analogistas e bayesianos têm sido amplamente utilizados na montagem de genomas sem uma referência explícita, para detecção de variantes genéticas, na predição de genes, elementos regulatórios, e sítios de metilação e modificação de histonas (modificações epigenéticas), na associação genótipo-fenótipo, na identificação taxonômica e predição da função metabólica em comunidades de microrganismos (metagenômica de amplicon e de shotgun), na quantificação da expressão gênica, análise de splicing alternativo, no agrupamento e classificação celular (para sequenciamento de genomas e transcriptomas de células únicas), e mesmo na evolução para a detecção de padrões de seleção natural ao nível molecular e na inferência filogenética.
O mesmo cenário também é encontrado em relação a proteínas e pequenas moléculas, com algoritmos de aprendizado de máquina clássicos, profundo (Deep Learning) e particularmente os grandes modelos de linguagem (LLMs) na predição de estruturas proteicas (AlphaFold, ESM), identificação de motivos e domínios proteicos, identificação de proteínas e modificações pós-traducionais, e na análise das interações proteína-proteína, proteína-pequenas moléculas e dinâmica molecular; bem como na reconstrução de vias metabólicas, predição de metabólitos desconhecidos e na modelagem de redes de interação em Biologia de Sistemas.
Uma área da Bioinformática/Biologia Computacional que particularmente vêm sendo grandemente beneficiada pela Visão Computacional assistida por Aprendizado Profundo é justamente a de análise de imagens biológicas e em todos os níveis de organização, desde o nível mais classicamente atrelado à Bioinformática como o molecular, até os níveis celular, tecidual e de características fenotípicas, que atualmente com o advento da Fenômica, requerem a análise automatizadas e geralmente de séries temporais de um volume maciço de dados.
Os Limites Morais da Inteligência Artificial na Manipulação de Dados Biológicos em Bioinformática / Biologia Computacional
A Bioinformática utiliza a Inteligência Artificial (IA) para analisar e interpretar grandes volumes de dados biológicos, como (meta)genomas, (meta)transcritomas, (meta)proteomas e (meta)metabolomas. A complexidade desses dados, combinada com a sensibilidade das informações que carregam, exige uma análise ética detalhada do uso de IA nessa área. A IA pode melhorar a medicina personalizada, prever riscos genéticos e acelerar descobertas científicas, mas, ao lidar com dados que revelam informações pessoais e familiares, surgem desafios éticos únicos que envolvem desde privacidade e consentimento até justiça e responsabilidade [7].
A privacidade dos dados biológicos é um princípio fundamental em bioética, especialmente quando envolve dados genéticos, que podem expor informações sobre saúde, histórico familiar e até identidade étnica [2]. A IA permite que esses dados sejam processados em larga escala, aumentando o risco de vazamentos ou usos não autorizados [4]. Inspirada na ética kantiana, que valoriza o respeito à dignidade e à privacidade, a proteção dos dados é essencial. No entanto, garantir a confidencialidade é um desafio, uma vez que muitos modelos de IA requerem grandes volumes de dados para funcionar de forma eficaz. É preciso criar sistemas robustos de segurança e políticas que assegurem que esses dados só serão utilizados com permissão explícita e para fins específicos [3].
O consentimento informado, derivado do princípio de autonomia, é crucial no uso de dados biológicos [2]. Contudo, em bioinformática, o consentimento é desafiador: os dados muitas vezes são reutilizados para finalidades diferentes das iniciais, e as pessoas podem não compreender todos os usos potenciais de seus dados. Isso exige uma abordagem ética que inclua transparência sobre os processos da IA, explicando claramente quais inferências podem ser feitas [7]. Uma possível solução é o consentimento dinâmico, onde o indivíduo renova seu consentimento para usos futuros, garantindo que a sua autonomia e escolha sejam respeitadas ao longo do tempo.
Os algoritmos de IA utilizados em bioinformática devem ser justos e livres de vieses. Dados biológicos, dependendo de sua origem, podem conter vieses que levam a preconceitos, como discriminação por etnia ou sexo. A justiça, segundo a ética de Rawls [11], sugere que a tecnologia deve beneficiar a todos de forma equitativa, sem desvantagens para grupos vulneráveis. Em bioinformática, isso implica um esforço para treinar algoritmos com dados diversos e representativos, além de monitorar ativamente as previsões feitas pela IA para garantir que decisões sejam tomadas de maneira justa e imparcial [9]. Medidas para a inclusão de diversidade no treinamento de IA são essenciais para que o uso desses dados respeite a justiça.
Esses princípios, fundamentais na ética médica, sugerem que o uso de IA na bioinformática deve promover o bem-estar e evitar danos [2]. A medicina personalizada é um exemplo de aplicação benéfica, mas também há riscos éticos. Seguradoras ou empregadores poderiam, por exemplo, usar dados genéticos para discriminar indivíduos, algo que representaria uma maleficência grave [10]. A governança ética na bioinformática deve prevenir esses usos discriminatórios e garantir que os avanços da IA beneficiem as pessoas, promovendo a saúde e a qualidade de vida sem explorar ou expor vulnerabilidades.
A transparência e a explicabilidade dos modelos de IA são essenciais para manter a confiança do público e garantir que eles sejam compreensíveis para especialistas e não-especialistas. Modelos de “caixa preta”, nos quais os processos de decisão não são totalmente compreensíveis, levantam questões sobre responsabilidade ética, pois médicos, pacientes e pesquisadores precisam entender como a IA chegou a certas conclusões para que possam tomar decisões informadas [4]. Além disso, a responsabilidade deve ser compartilhada entre desenvolvedores, empresas e instituições de saúde, assegurando que os erros ou abusos sejam corrigidos e que haja responsabilidade perante o público.
A manipulação de dados biológicos por IA em bioinformática representa um avanço científico, mas impõe também um conjunto de desafios éticos complexos. Garantir privacidade, promover justiça, assegurar o consentimento e manter a transparência são passos essenciais para o uso ético dessa tecnologia. Propostas para um framework ético de governança incluem auditorias regulares, comitês de ética especializados e políticas públicas que regulem o uso de IA, protegendo direitos humanos e promovendo o bem-estar social [3,7]. Somente ao integrar princípios éticos sólidos a bioinformática poderá avançar de forma responsável, maximizando os benefícios da IA e protegendo os direitos e a dignidade dos indivíduos.
Dado o avanço acelerado da IA, uma abordagem ética sólida não só promove o uso responsável dessas tecnologias, como também fortalece a confiança do público e dos financiadores nas inovações. A bioinformática, ao utilizar IA para manipulação e análise de dados biológicos, apresenta uma oportunidade única de transformar o setor de saúde e de pesquisa genética, mas exige uma atenção rigorosa aos impactos éticos e sociais que surgem com essas transformações.
A aplicação de princípios éticos – como privacidade, justiça, transparência e consentimento – deve ser apoiada por estruturas legais e normativas específicas. Por exemplo, legislações como o Regulamento Geral sobre a Proteção de Dados (GDPR) na União Europeia estabelecem padrões claros para o uso e compartilhamento de dados pessoais, sendo particularmente relevantes quando aplicados a dados de saúde e genéticos. Além disso, diretrizes internacionais, como as recomendadas pelo European Group on Ethics [3], oferecem frameworks que podem ajudar na formulação de políticas organizacionais e protocolos de uso ético de IA.
Para assegurar a implementação prática desses princípios, algumas medidas são sugeridas na literatura. Em primeiro lugar, as auditorias éticas regulares de algoritmos de IA poderiam identificar e mitigar vieses ou falhas de segurança, permitindo um monitoramento contínuo da justiça e da privacidade no uso desses dados [9]. Em segundo lugar, é fundamental promover uma “IA explicável”, onde os modelos e decisões da IA são transparentes e compreensíveis, garantindo que as decisões baseadas em IA sejam verificáveis e responsivas às necessidades éticas e legais [4].
O desenvolvimento de uma ética aplicada para IA em bioinformática também precisa considerar o impacto de longo prazo no bem-estar da sociedade. A justiça social requer que as inovações em IA beneficiem tanto os indivíduos quanto a coletividade, e não apenas grupos privilegiados. Para isso, os estudos e a prática ética sugerem a necessidade de inclusão de vozes diversas no desenvolvimento e aplicação de IA, prevenindo que comunidades vulneráveis sofram desproporcionalmente com os efeitos adversos de algoritmos tendenciosos ou uso indevido de dados [10,11].
Assim, a manipulação ética de dados biológicos na bioinformática exige um compromisso multifacetado: governança robusta, transparência nos processos, inclusão de diferentes perspectivas e um foco em proteger a dignidade humana. Isso reflete uma responsabilidade compartilhada entre pesquisadores, desenvolvedores, instituições de saúde e formuladores de políticas. Somente por meio dessa abordagem colaborativa é possível garantir que as inovações em bioinformática e IA sejam utilizadas de maneira justa, segura e benéfica para toda a sociedade.
Referências
[1] Azamat, A. (2021). Trans-ai: How to build true AI or real machine intelligence and learning. Онтология проектирования, 11(4 (42)), pp.402-421.
[2] Beauchamp, T. L., & Childress, J. F. (2013). Principles of Biomedical Ethics. Oxford University Press.
[3] European Group on Ethics in Science and New Technologies (EGE). (2018). Statement on Artificial Intelligence, Robotics and ‘Autonomous’ Systems.
[4] Floridi, L. (2023). The ethics of artificial intelligence: Principles, challenges, and opportunities.
[5] Hoffmann, C.H., 2022. The quest for a universal theory of intelligence: The mind, the machine, and singularity hypotheses. Walter de Gruyter GmbH & Co KG.
[6] Haenlein, M. and Kaplan, A., 2019. A brief history of artificial intelligence: On the past, present, and future of artificial intelligence. California management review, 61(4), pp.5-14.
[7] Jobin, A., Ienca, M., & Vayena, E. (2019). “The global landscape of AI ethics guidelines.” Nature Machine Intelligence, 1(9), 389-399.
[8] McCarthy, J., Rochester, N. and Shannon, C., 1956. Dartmouth workshop.
[9] Mittelstadt, B. D., Allo, P., Taddeo, M., Wachter, S., & Floridi, L. (2016). “The ethics of algorithms: Mapping the debate.” Big Data & Society, 3(2).
[10] O’Neil, C. (2016). Weapons of Math Destruction: How Big Data Increases Inequality and Threatens Democracy.
[11] Rawls, J. (1971). A Theory of Justice. Harvard University Press.
[12] Turing, A.M. (1950). Computing machinery and intelligence.