
Minha história na bioinformática foi se construindo pouco a pouco, em um caminho sinuoso que me levou a explorar diferentes áreas e desafios. Tudo começou com a escolha pela citogenética na graduação, onde tive a primeira noção de como a biologia molecular se entrelaça com a tecnologia. Naquele momento, eu nem imaginava que isso abriria portas para a bioinformática, mas, aos poucos, fui mergulhando cada vez mais nesse universo fascinante. O contato com técnicas de sequenciamento de genes e a análise de dados genômicos foi me revelando como a computação poderia ser uma aliada poderosa da biologia. Ao longo dos anos, com o mestrado, doutorado e pós-doutorado, fui consolidando esse caminho, que de início parecia cheio de curvas, mas que, no fim das contas, me levou exatamente onde eu queria estar: desenvolvendo soluções para a saúde, a agropecuária e a ciência de dados. A bioinformática, para mim, é esse espaço dinâmico, onde a curiosidade e a ciência de vanguarda se encontram, e, mesmo com os desafios – seja como mulher, mãe ou pesquisadora – sigo com a mesma paixão e vontade de aprender.
Autora: Fernanda Nascimento Almeida (0000-0003-3086-454X)
Revisão: Aline de Paula Dias da Silva (0009-0003-5022-0642); Tatiane Senna Bialves (0000-0002-3827-2859)
As “linhas sinuosas” para a Bioinformática
Minha trajetória acadêmica começou em Ilhéus, na Universidade Estadual de Santa Cruz (UESC), onde iniciei meu bacharelado em Ciências Biológicas com ênfase em Biomedicina, em 1998. Desde o início, fui movida pela curiosidade e pelo desejo de entender os mecanismos biológicos por trás da vida. Logo que entrei na universidade, busquei oportunidades na iniciação científica. Entre as muitas opções que estavam disponíveis na época, escolhi a área de citogenética, uma escolha que marcaria o início do meu envolvimento profundo com a ciência.
A escolha pela citogenética foi uma oportunidade que ampliou a minha percepção sobre os processos biológicos em um nível molecular e genético. Nesse campo, tive a chance de trabalhar diretamente com a análise dos cromossomos, o que me permitiu entender melhor como alterações em sua estrutura e número podem influenciar características fenotípicas e o desenvolvimento de doenças. Além de fortalecer minha base em genética, essa experiência também despertou meu interesse pela interseção entre biologia e tecnologia. Sob a orientação de uma professora inspiradora, pude aprender não apenas técnicas importantes de análise citogenética, mas também a essência da pesquisa científica. Fiz amigos que partilhavam do mesmo entusiasmo pela investigação e, juntos, vivemos o dia a dia do laboratório, das coletas em campo, experimentando, discutindo ideias e nos preparando para o futuro. Foi um período de grande aprendizado e, acima de tudo, uma época em que compreendi o significado de ser cientista: questionar, explorar e buscar respostas para os enigmas da natureza.
Ao final da graduação, tive a oportunidade de realizar meu trabalho de conclusão de curso fora do estado da Bahia, em São José dos Campos, na Universidade do Vale do Paraíba (UNIVAP). Foi uma aventura emocionante, pois além de ser a primeira vez que me mudava para outra cidade por conta da ciência, o projeto em que trabalhei envolvia o sequenciamento de genes humanos. Esse projeto representa, para mim, a realização de um sonho. Sempre fui fascinada pela genética, e trabalhar com genética e biologia molecular me fez mergulhar ainda mais fundo nesse campo. Mais do que isso, foi ali, no laboratório da UNIVAP, que tive meus primeiros contatos com a área de bioinformática, isso foi no início de 2001. Trabalhei com a junção e identificação de transcritos humanos, utilizando técnicas de sequenciamento, montagem e BLAST, o que ampliou minha visão sobre como a computação poderia se integrar à biologia para oferecer respostas mais rápidas e eficientes.
Com a conclusão da graduação, meu interesse pela bioinformática só aumentou, e o próximo passo natural foi o mestrado. Ingressei no Laboratório Nacional de Computação Científica (LNCC), em Petrópolis, onde tive a oportunidade de trabalhar com grandes nomes da área e atuar em projetos inovadores. Durante o mestrado, implementei um banco de dados, o ProBacter, destinado a integrar dados genômicos e proteômicos de bactérias patogênicas associadas a plantas. O objetivo desse projeto era facilitar a identificação de proteínas relacionadas à patogenicidade e resistência, permitindo que os pesquisadores pudessem entender melhor os mecanismos de ação dessas bactérias em plantas agrícolas. A pesquisa envolvia desafios técnicos complexos, como o desenvolvimento de uma plataforma web de fácil acesso para pesquisadores e a organização de grandes volumes de dados biológicos. No entanto, esses desafios me motivaram ainda mais, pois percebi o impacto que a bioinformática poderia ter em áreas como a agricultura e o combate a doenças de plantas. Foram dois anos intensos de muito aprendizado que resultaram na apresentação da minha dissertação em um evento internacional importante, como a conferência anual da ISMB (International Society for Computational Biology), um dos maiores congressos de bioinformática do mundo.
Após o mestrado, ingressei no doutorado no Programa Interunidades de Pós-Graduação em Bioinformática da Universidade de São Paulo (USP), um período que trouxe ainda mais desafios, mas também grandes realizações. Minha pesquisa se concentrou no uso da proveniência de dados para a extração de conhecimento em sistemas de hemoterapia. Isso significava aplicar conceitos da ciência de dados e da computação para otimizar a análise de informações sobre doadores de sangue, buscando soluções que pudessem melhorar a triagem e a prevenção de doadores de sangue. O trabalho envolvia a análise de grandes volumes de dados biomédicos do Hemocentro de São Paulo e me colocou em contato com especialistas da área da saúde, tanto no Brasil quanto no exterior. Um dos aspectos mais recompensadores dessa fase foi poder ter minha pesquisa sendo apresentada em conferências internacionais, como o AABB Annual Meeting (Association for Advancement of Blood & Biotherapies) em Baltimore, nos Estados Unidos, onde a relevância da bioinformática na saúde foi amplamente discutida.
A pesquisa em hemoterapia foi extremamente gratificante, mas não foi isenta de desafios. Além das exigências acadêmicas, enfrentei o preconceito sutil que ainda existe em áreas técnicas, especialmente sendo mulher e formada em biomedicina em um campo que, por vezes, valoriza mais a computação e as engenharias. No entanto, essas dificuldades só fortaleceram ainda mais minha determinação, e foi com essa mesma resiliência que segui em frente para o pós-doutorado na Universidade Federal de Juiz de Fora (UFJF). Lá, trabalhei em projetos de bioinformática aplicados à agropecuária, colaborando com a Embrapa em iniciativas voltadas ao melhoramento genético de bovinos. O projeto envolvia a identificação de marcadores SNP (polimorfismos de nucleotídeo único) em zebuínos leiteiros, com o objetivo de melhorar a produtividade e resistência das raças. Esse trabalho foi um dos meus primeiros grandes contatos com a aplicação prática da bioinformática em setores importantes para a economia brasileira.
A maternidade motivacional
Em 2014, a minha vida pessoal passou por uma grande transformação: realizei mais um sonho, tornei-me mãe. Confesso que não foi fácil conciliar a maternidade e senti na pele os anseios e angústias, não somente no contexto da maternidade, mas também no âmbito acadêmico. Infelizmente, a academia nem sempre é receptiva com mulheres que são mães e pesquisadoras. O período da maternidade levou a uma interrupção significativa na minha carreira e, consequentemente, na minha produtividade científica. Essa lacuna no currículo, muitas vezes inevitável, é ainda hoje alvo de julgamentos severos por parte dos órgãos de fomento do nosso país. Esse espaço em branco é frequentemente visto como uma falha, ignorando o contexto maior. Essa realidade reforça a necessidade de políticas públicas que considerem a maternidade como um fator legítimo na trajetória de uma cientista, reconhecendo as dificuldades inerentes a esse período e incentivando iniciativas para apoiar mulheres pesquisadoras.
Filhos, longe de serem um impedimento para o desenvolvimento profissional, deveriam ser vistos como parte integrante da jornada acadêmica de uma mulher, pois a maternidade não diminui o potencial intelectual ou a capacidade de contribuição científica. No entanto, é importante reconhecer que mães enfrentam desafios e demandas diferentes daqueles que não são pais, o que exige adaptações no ambiente acadêmico e nas políticas de avaliação. Essas adaptações poderiam incluir a flexibilização de prazos para submissão e entrega de projetos, a implementação de editais específicos que considerem a maternidade como critério, e a criação de programas de suporte dentro das instituições, como creches universitárias, redes de apoio parental e períodos sabáticos direcionados para retomada de projetos após a maternidade.
Um ponto crucial é que a experiência da maternidade pode trazer qualidades valiosas para a vida acadêmica. A organização, a capacidade de adaptação, o gerenciamento de tempo e a resiliência, características muitas vezes desenvolvidas no contexto da maternidade, são habilidades que contribuem significativamente para o trabalho científico. A maternidade deveria ser vista como um elemento complementar à carreira, capaz de agregar novas perspectivas e formas de enfrentar os desafios acadêmicos.
A vida acadêmica chega a ser injusta e até opressora nesse sentido, forçando a produção de publicações a todo custo, como se apenas a quantidade importasse. Isso sem considerar que a qualidade, a profundidade e o impacto dos trabalhos realizados deveriam ser muito mais valorizados. No entanto, longe de ser um obstáculo, a maternidade me motivou ainda mais. Ser mãe não me fez menos profissional; pelo contrário, me tornou mais focada, organizada e determinada. Aprendi a valorizar meu tempo e a equilibrar minha vida pessoal com a carreira, o que, de certa forma, melhorou minha eficiência como pesquisadora.
Mesmo com esses obstáculos, continuei avançando e, em 2017, fui aprovada como professora adjunta da Universidade Federal do ABC (UFABC). Esse foi um dos marcos mais importantes da minha carreira profissional, pois representou a concretização de anos de esforço e dedicação. Na UFABC, além de lecionar disciplinas como Introdução à Bioinformática, Bioestatística, Biologia Celular e Computação Científica Aplicada a Problemas Biológicos, também me tornei uma pesquisadora ativa e orientadora. Minha linha de pesquisa atual abrange desde a análise comparativa de genomas até a aplicação de técnicas de inteligência artificial para dados biomédicos. Além disso, coordeno o grupo de pesquisa BHIG (Bioinformatics and Health Informatics Group) e o LaBIC (Laboratório de Bioinformática e Inteligência Computacional), onde eu e meus orientandos desenvolvemos soluções para a área da biologia e saúde.
Um dos momentos mais difíceis e, ao mesmo tempo, gratificantes da minha profissão foi o trabalho desenvolvido durante a pandemia de COVID-19. Além de enfrentar os desafios da crise sanitária, acabei me tornando professora da minha filha, que estava entrando na alfabetização durante esse período. Tive que buscar métodos e estratégias para ajudá-la a aprender em casa, enquanto, ao mesmo tempo, ministrava disciplinas no formato remoto. Esse também foi o período em que mais ministrei disciplinas, pois vi muitos docentes sendo afastados por motivos de saúde. Mesmo com essa imensa sobrecarga, fui convidada a fazer parte do Núcleo de Monitoramento da Pandemia da UFABC [1], onde discutíamos a condição sanitária, o retorno seguro às atividades e publicávamos boletins mensais sobre a situação da COVID-19 no estado de São Paulo, e do projeto para criação da Plataforma COVIData. A COVIData nasceu da necessidade urgente por respostas à emergência sanitária, assim, coordenei um grupo dedicado de alunos da UFABC (de diferentes cursos de graduação, como: ciência da computação, biologia e engenharia biomédica) no gerenciamento do desenvolvimento da plataforma. A ferramenta web foi criada primeiramente para identificar, monitorar e analisar casos suspeitos de COVID-19 [2]. Em poucos meses, a COVIData se tornou importante para o controle da pandemia em muitas regiões do ABC paulista, oferecendo uma forma ágil de registrar e analisar dados sobre a disseminação do vírus. A plataforma foi utilizada por profissionais de saúde de cidades como Ribeirão Pires, Rio Grande da Serra e São Bernardo do Campo para tomar decisões mais informadas e efetivas no combate à pandemia (Figura 1). O sucesso desse projeto foi tão significativo que a COVIData registrou duas patentes, consolidando-se como uma ferramenta eficaz na luta contra o coronavírus. Receber esse reconhecimento foi uma grande conquista, pois mostrou que a bioinformática pode ter um impacto direto e positivo na vida das pessoas, especialmente em momentos críticos como uma pandemia global. Figura 1. Imagens de divulgação da plataforma COVIData em parceria com o Consórcio Intermunicipal Grande ABC. A imagem ilustra materiais de comunicação voltados à orientação da população sobre sintomas da COVID-19 e ao uso da ferramenta para triagem virtual. FONTE: UFABC, Consórcio ABC, Clique ABC.
Figura 1. Imagens de divulgação da plataforma COVIData em parceria com o Consórcio Intermunicipal Grande ABC. A imagem ilustra materiais de comunicação voltados à orientação da população sobre sintomas da COVID-19 e ao uso da ferramenta para triagem virtual. FONTE: UFABC, Consórcio ABC, Clique ABC.
Minhas Contribuições na Pesquisa
Ao longo de minha trajetória, minhas linhas de pesquisa evoluíram para acompanhar as inovações e desafios da bioinformática, sempre com o objetivo de aplicar a tecnologia de forma a resolver problemas reais e gerar impacto na saúde, na biologia e em outras áreas interdisciplinares. Minhas principais áreas de atuação se concentram no desenvolvimento de bancos de dados biológicos, análise comparativa de genomas, proveniência de dados em sistemas biomédicos, bioinformática aplicada à saúde e ao meio ambiente, além de inteligência artificial aplicada a grandes volumes de dados biológicos.
Bancos de Dados Biológicos
A criação, gestão e análise de bancos de dados biológicos é uma das minhas principais áreas de atuação. Durante o mestrado, desenvolvi o ProBacter, já mencionado acima. Esse projeto visava facilitar a pesquisa de patógenos de grande relevância econômica, ajudando os cientistas a identificarem proteínas relacionadas à resistência e à virulência de doenças em culturas agrícolas.
Esse interesse por bancos de dados se expandiu com o tempo, e hoje trabalho no desenvolvimento de sistemas que integram e organizam grandes volumes de dados genômicos e clínicos. Esses bancos de dados são ferramentas essenciais para o avanço da bioinformática, especialmente em estudos que envolvem doenças genéticas, onde é fundamental cruzar dados de diferentes fontes para identificar padrões genômicos e biomarcadores.
Análise Comparativa de Genomas
A análise comparativa de genomas é um dos campos mais promissores dentro da bioinformática e tem sido um foco constante em meus projetos de pesquisa. O objetivo é comparar genomas de diferentes organismos ou linhagens para identificar diferenças genéticas que possam explicar variações em fenótipos, como resistência a doenças, adaptação ao ambiente ou produção de substâncias bioativas. Essa linha de pesquisa envolve o uso de ferramentas computacionais para comparar sequências de DNA de microrganismos patogênicos e organismos de interesse agrícola.
Na Embrapa Gado de Leite, em Minas Gerais, participei de um projeto voltado para a análise comparativa de genomas de bovinos zebuínos, com o objetivo de identificar marcadores SNP que pudessem ser utilizados para melhorar a produtividade e a resistência desses animais. Essa pesquisa contribuiu diretamente para o setor agropecuário, otimizando a seleção genética e o manejo animal [3].
Proveniência de Dados em Sistemas Biomédicos
Outro foco central da minha pesquisa é a proveniência de dados, uma área que explora como os dados são gerados, manipulados e utilizados em sistemas de informação biomédica. Durante o doutorado, dediquei-me a estudar como a proveniência de dados pode ser aplicada em sistemas de hemoterapia, com o objetivo de otimizar o uso de informações de doadores de sangue em larga escala. Através da análise detalhada de dados biomédicos, conseguimos extrair conhecimento valioso que poderia ser usado para ajudar a melhorar a triagem de doadores e o tratamento para evitar casos de anemia após a doação [4].
A proveniência de dados é especialmente crucial em sistemas biomédicos, onde garantir a integridade, a origem e a rastreabilidade das informações não é apenas uma questão técnica, mas uma necessidade vital para o funcionamento seguro e eficiente desses sistemas. A proveniência possibilita que se acompanhe todo o ciclo de vida dos dados, desde a sua coleta até a análise e utilização final, garantindo que qualquer alteração ou manipulação possa ser rastreada. Isso é particularmente importante em ambientes de saúde, como hospitais e laboratórios, onde os dados de pacientes, como prontuários eletrônicos, exames e históricos médicos, são utilizados para decisões clínicas que afetam diretamente o tratamento e o prognóstico dos pacientes.
A ausência de uma proveniência robusta pode comprometer a confiabilidade dessas informações, levando a diagnósticos errados, prescrições inadequadas ou tratamentos incorretos. Por exemplo, ao utilizar prontuários eletrônicos, é fundamental saber a origem de cada dado inserido, quem o modificou e quando, especialmente em casos críticos que exigem a máxima precisão. Além disso, a proveniência de dados pode ser aplicada a ensaios clínicos, onde rastrear a origem e manipulação dos dados é essencial para garantir que os resultados dos estudos sejam válidos e reprodutíveis [4]. Essa pesquisa também se aplica à genética, onde a proveniência ajuda a rastrear o processamento de sequências genéticas, garantindo a precisão e integridade dos dados analisados.
Inteligência Artificial em Bioinformática
A aplicação de técnicas de inteligência artificial (IA) em bioinformática é uma das linhas de pesquisa que mais me fascina e que mais tem crescido nos últimos anos. Com o advento de tecnologias de Machine Learning (ML) e Deep Learning (DL), que surgiram como campo de estudo a partir de meados do século XX, com contribuições de figuras como Frank Rosenblatt, que desenvolveu o perceptron nos anos 1950, essas técnicas evoluíram para ferramentas sofisticadas que permitem processar e analisar volumes massivos de dados biológicos com eficiência [4]. As redes neurais profundas, parte do DL, começaram a ganhar destaque nos anos 1980 e 1990 com o avanço da computação e o desenvolvimento de algoritmos mais eficientes para aprendizado e reconhecimento de padrões [5].
Em meus projetos, essas tecnologias têm sido fundamentais para prever padrões de doenças, identificar novos biomarcadores e realizar análises complexas de dados genômicos e proteômicos em larga escala. Um exemplo disso é o trabalho utilizando técnicas de Machine Learning aplicadas à predição de viabilidade de embriões em procedimentos de fertilização in vitro (FIV). Neste projeto, utilizamos redes neurais profundas para analisar imagens e dados clínicos de embriões, buscando identificar características que correlacionam com a probabilidade de sucesso nos procedimentos de FIV.
Além disso, minhas pesquisas também envolvem a aplicação de ML em problemas como a predição de prognósticos de doenças, como o câncer, por exemplo, em colaboração com alunos de graduação. No estudo sobre a predição de prognóstico de câncer de pulmão utilizando técnicas de aprendizado de máquina em registros de saúde e dados de expressão gênica, aplicamos modelos de Support Vector Machine (SVM) e redes neurais artificiais para prever a sobrevida de pacientes com câncer de pulmão, utilizando dados genéticos e clínicos extraídos de microarrays. A implementação foi feita utilizando ferramentas de código aberto, e o desempenho do SVM destacou-se, mostrando ser uma técnica poderosa para modelos de classificação binária em espaços de alta dimensionalidade.
Outro trabalho relevante que explora o potencial do ML é o descrito em [7], onde discutimos como a proveniência de dados pode melhorar a qualidade dos modelos preditivos aplicados em saúde, assegurando maior confiança e rastreabilidade das informações usadas nos modelos de IA. Essa pesquisa é uma base importante para a construção de sistemas mais robustos e confiáveis na área de bioinformática.
Esses exemplos demonstram como ML e DL têm sido ferramentas valiosas na transformação da bioinformática, permitindo não apenas a análise de grandes volumes de dados, mas também oferecendo ideias que ajudam a avançar tanto na medicina quanto em áreas biotecnológicas.
Bioinformática Aplicada à Saúde
Dentro da bioinformática, a saúde sempre foi uma das áreas mais relevantes e desafiadoras. Ao longo da minha carreira, tenho me dedicado a projetos que utilizam a bioinformática para analisar grandes volumes de dados biomédicos, com o objetivo de melhorar a tomada de decisões clínicas e oferecer novas perspectivas no tratamento de doenças. Isso inclui o desenvolvimento de bancos de dados clínicos, análise de dados genômicos e aplicação de IA em diagnósticos e tratamentos personalizados.
Uma das minhas maiores contribuições nesse campo foi a análise de dados de doadores de sangue. Além disso, oriento diversos alunos em projetos que envolvem o uso de aprendizado de máquina para prever desfechos clínicos, como a sobrevivência de pacientes com câncer, e na criação de modelos para melhorar o diagnóstico de doenças genéticas. Outra vertente inovadora na minha pesquisa é a exploração da tecnologia blockchain na saúde digital. No trabalho apresentado em [8], investigamos como o blockchain pode ser aplicado para melhorar a segurança e a interoperabilidade dos dados de saúde no Brasil (Figura 2). A tecnologia oferece um sistema descentralizado e seguro para o armazenamento e compartilhamento de registros médicos, garantindo a integridade e a privacidade das informações dos pacientes.
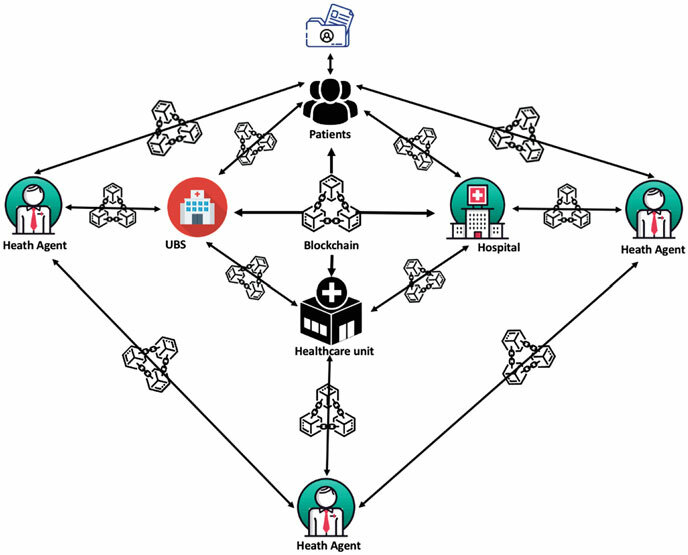 Figura 2. Distribuição em rede do blockchain para gerenciamento de dados de pacientes no sistema de saúde. A imagem ilustra como agentes de saúde, unidades básicas de saúde (UBS), hospitais e unidades de saúde interagem através de uma infraestrutura de blockchain. FONTE: Yamada & Almeida, 2022 [8].
Figura 2. Distribuição em rede do blockchain para gerenciamento de dados de pacientes no sistema de saúde. A imagem ilustra como agentes de saúde, unidades básicas de saúde (UBS), hospitais e unidades de saúde interagem através de uma infraestrutura de blockchain. FONTE: Yamada & Almeida, 2022 [8].
Apesar do grande potencial do blockchain na saúde pública, sua implementação efetiva ainda enfrenta desafios significativos. Isso inclui a necessidade de infraestrutura tecnológica robusta, treinamento adequado para os profissionais de saúde e regulamentações claras que garantam a interoperabilidade e o uso seguro dessa tecnologia. Embora avanços tenham sido feitos em projetos piloto no setor privado e em algumas iniciativas governamentais, é provável que ainda sejam necessários, na minha opinião, ao menos 5 a 10 anos para que o blockchain esteja amplamente disponível no sistema público brasileiro. Esse período dependerá da continuidade de investimentos em tecnologia, do estabelecimento de políticas públicas específicas e da superação de barreiras como resistência à mudança e custos iniciais elevados.
Isso é especialmente importante em um país como o Brasil, onde a integração de dados de diferentes fontes pode otimizar a gestão da saúde pública e privada, além de melhorar a qualidade do atendimento ao paciente. O blockchain tem o potencial de revolucionar a gestão de dados na saúde, assegurando que as transações e atualizações em registros médicos sejam rastreáveis e seguras, contribuindo para uma maior eficiência no tratamento dos pacientes e na administração de sistemas de saúde públicos e privados. No entanto, para alcançar essa transformação, será crucial fomentar colaborações entre o setor público, privado e, principalmente, o setor acadêmico, além de sensibilizar os gestores de saúde sobre os benefícios dessa tecnologia.
Análise de Grandes Volumes de Dados (Big Data)
Com o aumento exponencial da quantidade de dados biológicos disponíveis, a análise de grandes volumes de dados (big data) se tornou um componente vital na bioinformática moderna. Minhas pesquisas focam também na criação de plataformas e ferramentas que possam processar e integrar esses dados de forma eficiente, proporcionando aos pesquisadores e médicos acesso a informações mais detalhadas e úteis.
Essa linha de pesquisa é aplicada tanto na saúde quanto na agricultura, onde big data tem o potencial de revolucionar práticas de manejo, seleção genética e diagnóstico. A utilização de ferramentas de big data em bancos de dados biológicos permite a análise de informações de diferentes fontes e o cruzamento de dados para gerar novos conhecimentos e descobrir padrões ocultos.
Por fim, minha trajetória até aqui sempre foi movida por desafios e, ao longo dos anos, enfrentei muitos deles, desde o preconceito por ser mulher e biomédica até as dificuldades de conciliar a vida acadêmica com a maternidade (até hoje isso é uma dificuldade encontrada não somente por mim, mas por muitas pesquisadoras!). No entanto, é gratificante observar como a bioinformática tem atraído cada vez mais mulheres. Hoje, vejo com alegria que muitas das minhas colegas, que enfrentaram seus desafios, não desistiram e continuam contribuindo de forma significativa para o campo. Mulheres inspiradoras que se dedicam à ciência e mostram que é possível combinar paixão, competência e perseverança para alcançar grandes realizações.
Ainda que eu tenha enfrentado dificuldades ao longo do caminho, mantenho a paixão pela bioinformática que desenvolvi no início da minha história como pesquisadora. Continuo movida pelo desejo de aprender, ensinar e contribuir para a ciência, independentemente dos obstáculos. Ser diferente dos estereótipos da área me trouxeram desafios extras, mas também fortaleceu minha determinação, sempre segui em frente, nunca desisti! E hoje, como docente, pesquisadora e orientadora, tenho o privilégio de usar essa experiência para ajudar a formar as próximas gerações de cientistas. Continuo acreditando no poder transformador da educação e da ciência, e essa crença me motiva a seguir em frente, enfrentando novos obstáculos com a mesma paixão que me trouxeram até aqui.
Referências
[1] Universidade Federal do ABC. Boletim Pandemia – UFABC. Disponível em: https://www.ufabc.edu.br/sobre-o-coronavirus/boletim-pandemia. Acesso em: 25 nov. 2024.
[2] Gandolfi, B. L., Merino, C. S. R., da Silva, V. I., Costa, D. S., Fiali, G. M., Carvalheiro, A. S., da Silva, L. R. C., Rocha, C. C., Lins, G. B., Leite, S. C., & Almeida, F. N. (2022). COVIData: A Web Platform for Tracking, Classification and Monitoring Cases Suspects of COVID-19. In IX Latin American Congress on Biomedical Engineering and XXVIII Brazilian Congress on Biomedical Engineering. Springer Nature Switzerland.
[3] de Oliveira, F.C., Borges, C.C.H., Almeida, F.N. et al. SNPs selection using support vector regression and genetic algorithms in GWAS. BMC Genomics 15 (Suppl 7), S4 (2014). https://doi.org/10.1186/1471-2164-15-S7-S4
[4] Almeida, F. N., Sabino, E. C., Tunes, G., Schreiber, G. B., da Silva, P. P. S. B., Carneiro-Proietti, A. B. F., Ferreira, J. E., & Mendrone-Junior, A. (2013). Predictors of low haematocrit among repeat donors in São Paulo, Brazil: Eleven year longitudinal analysis. Transfusion and Apheresis Science, 49(3), 553-559. https://doi.org/10.1016/j.transci.2013.09.009
[5] Schmidhuber, J. (2015). Deep Learning in Neural Networks: An Overview. Neural Networks, 61, 85-117. DOI: 10.1016/j.neunet.2014.09.003
[6] LeCun, Y., Bengio, Y. & Hinton, G. Deep learning. Nature 521, 436–444 (2015). https://doi.org/10.1038/nature14539
[7] Bertolini, C. T., Leite, S. C., & Almeida, F. N. (2020). Predicting Cancer Patients’ Survival Using Random Forests. In Advances in Bioinformatics and Computational Biology (Vol. 11347). Springer. ISBN: 978-3-030-46416-5.
[8] de Oliveira Vargas Yamada, T., Nascimento Almeida, F. (2022). Perspectives of Blockchain in Digital Health in Brazil. In: Misra, S., Kumar Tyagi, A. (eds) Blockchain Applications in the Smart Era. EAI/Springer Innovations in Communication and Computing. Springer, Cham. https://doi.org/10.1007/978-3-030-89546-4_1